Summary
Parking lot for ACE Infrastructure knowledge transfer topics (aka “The Runbook”). Focus for now is on content; not structure. I’ll sort the latter out as things grow. In the meantime, things might look a little unorganized and that’s okay.
On-Call
Procedures & Responsibilities
- Monitor and respond to support questions posted in the ecdi-ace-infra-support Slack channel.
- Monitor the On-Call ZenHub Issues Board and respond to any new tickets within 24 hours and address in accordance with their priority rating:
- PO-P1: These tickets represent outages or non-workaround blockages and should be prioritized above everything else, including meetings.
- P2: These tickets are less severe than P0-P1, but the on-call engineer should attempt to resolve during their shift, time permitting.
- P3-P4: These tickets represent standard requests and are NOT the responsibility of the on-call engineer to resolve, but they should attempt to triage within their shift if they have enough information and knowledge to do so. Where they need more information, they should reach out to the ticket submitter with questions. Where they need triage assistance, they should take time during the Wednesday infrastructure meeting to collaborate with team SME’s to assess level of effort and timebox.
- Perform an explicit Monday morning handoff to the succeeding on-call engineer, during which they will provide context necessary to ensure a smooth transition with no dropped issues.
- Any partially completed issues should be reassigned from
gredacs1_rocheto themselves for completion. When reassigning, also remove theoncalltag so the issue no longer shows up on theoncallboard.
Procedures
OnCall Resources
| Resource | Description |
|---|---|
| On-Call ZenHub Issues Board | This links to our ZenHub board to show all issues tagged with the oncall tag. If you’re on call you should probably pin this page in your browser as this will be where most of your work starts. |
Priorities Defined

Capacity Planning & Issue Triaging
Capacity Model
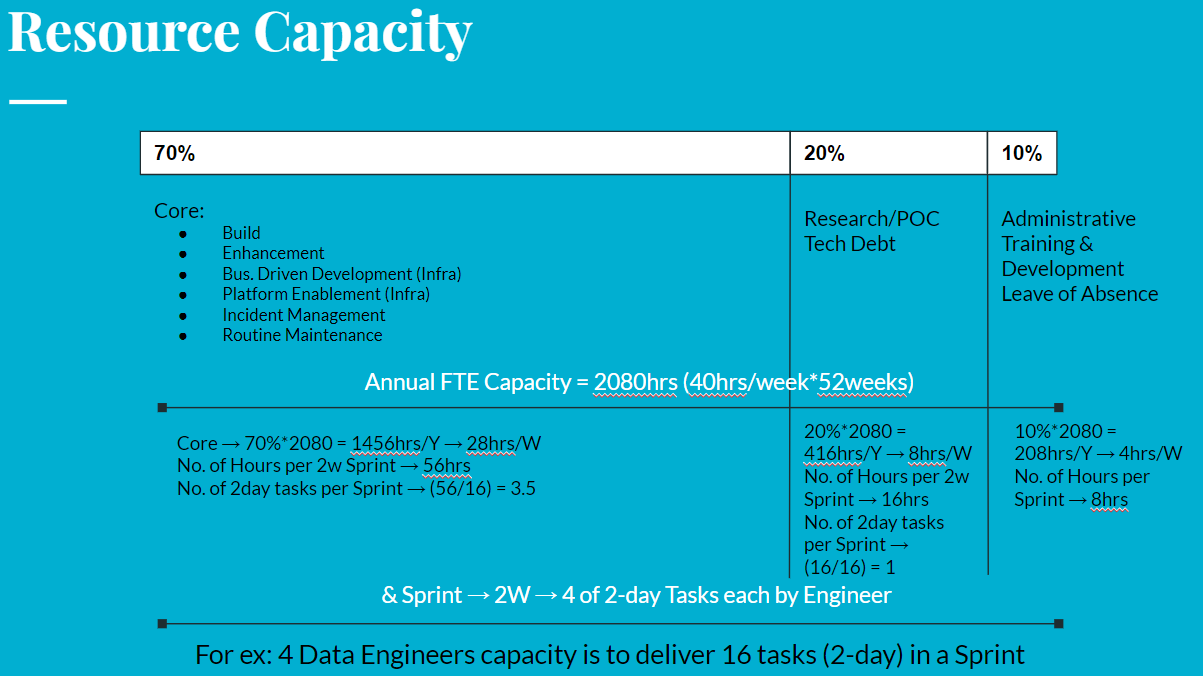
More on this later. Just want to capture for now.
Estimating Level of Effort (LOE) with Story Points
Matrix
Below is our first pass at defining a story point to cheatsheet. We agreed on April 20, 2023 that we’re going to take it out for a walk and see how it feels. We’ll collectively decide if/when to make adjustments based on feedback. Our objective here is simply to get us all working off the same script We agreed to the points-to-time conversion before I added the three dimensions (uncertainty, complexity, effort) to the table. As a result, it’s somewhat incomplete as doesn’t yet account for size mixture for each dimension. I will work on this later.
| Story Points | Uncertainty | Complexity | Effort | Estimated Time Conversion^1^ |
|---|---|---|---|---|
| 1 | 2x-small | 2x-small | 2x-small | about 30 minutes |
| 2 | x-small | x-small | x-small | about an hour |
| 3 | small | small | small | about 1/2 day |
| 5 | small | small | medium | about 1 day |
| 8 | medium | medium | medium | 2-3 days |
| 13 | large | large | large | about a week (Perhaps should be broken into smaller tasks) |
| 21 | x-large | x-large | x-large | about two weeks (Really should be broken into smaller tasks |
| 40 | unused |
^1^ Story points are intended as a unit of measurement of the uncertainty, complexity and effort of a task. They are not intended to convert directly to time and some Agile experts consider it an antipattern to do so. That said, we’ve not quite shaken this urge so I’ve added an Estimated Time Conversion column for reference.
Theory
Work in progress
I want to share some chunks of knowledge from my research on this topic as there’s still a bit of contention on the topic of story points.
What is a story point
A story point is a unitless measurement of size based on:
- complexity
- uncertainty
- effort
It is not intended to serve as an estimate of the amount of time it will take. Time gets figured out over time via velocity charts.
Reference
For great insight on the topic please read the following articles:
- Estimating Work Using Story Points from ZenHub: Includes lessons learned from an award winning research paper that Microsoft published on this topic.
- TeamHood Story Point Estimation: Provides tips and examples for doing story point estimation.
- CheatSheet for Story Point Sizing:
- Fibonacci scale: Primer on the story point number system used by ZenHub.
NooB Q&A
This section is intended to provide some answers to new team-members’ commonly asked questions. Its genesis is a great list of questions posed to me by a new member of the team in advance of a 1:1 meeting. Rather than rattle off answers, I’ve chosen to capture them here for everyone’s benefit. This section is intended to be high-level, but I’ll link to further documentation when and where we have it.
What is our cloud authentication & authorization model?
As of July 2022, we’re still reliant on IAM. Beginning August 2022, we are prioritizing a migration to Roche SSO whereby users login to AWS using their Roche SSO credentials with authorization determined by their Roche Active Directory (RADA) group assignments. We’re also planning to implement AWS IAM attribute-based access control (ABAC) to improve our model’s flexibility, especially for users who span RADA groups.
How is AWS billing managed?
This is still a bit of a question mark, to be honest. We have implemented attributes (tags) to facilitate a chargeback model:
- Function
- Team
- WBS Code
- Project
but to my knowledge we’re not yet leveraging them. I will inquire with Murali and Saima and update this answer with more information.
How do you provision infrastructure?
This has evolved since I (Todd) joined the organization in March 2020. I started with Terraform OSS; then tried Terragrunt, a Terraform wrapper, in an effort to DRY out our code a bit before the organization finally approved purchase of Terraform Cloud (TFCloud). Today we use TFCloud with tremendous success so do not expect us to abandon that anytime soon.
NOTE: As of July 2022, we still have a few low-touch legacy workspaces that have not been migrated from Terraform OSS and Terragrunt to TFCloud, but we expect to be 100% transitioned to TFCloud by EOY 2022.
Please see our TFCloud page for additional details.
How does ACE manage application code releases?
We expect our application developers to manage their own code releases using automated workflows that we’ve developed and assisted them in implementing. The level of automation depends on whether their applications are instance based or container based.
NOTE: As of July 2022, we are in the process of migrating CI/CD, along with all of our code, from GitLab (w/ GitLab CI) to GitHub (w/ GitHub Actions so this topic is in flux. Expect updates as Saeedeh takes charge of this work and provides documentation.
How does ACE manage platform monitoring?
Platform monitoring is in a bit of a limbo state due to the fact that the past few folks responsible for monitoring have come and gone, leaving it somewhat disjointed.
NOTE: As of June 2022, Saeedeh has assumed primary responsibility for our monitoring stack and is in the process of refactoring it to support our needs. For more information, contact Saeedeh or checkout our Observability page.
Does Roche have a central Site Reliability Engineering (SRE) Team or do we manage that ourselves?
Roche has access to account information and will occasionally reach out to us on matters related to security and billing, but the reliability of all infrastructure and applications deployed to the ACE-Prod account is our team’s responsibility.
We (ACE Infra) are SRE’s for the ACE production AWS account with a few minor caveats.
- We are granted full administrative rights to our ACE-Prod AWS account.
- This account is part of an AWS Organization structure managed centrally by Roche so org-level actions must be requested of Roche.
- There are a few baseline security tools implemented at the org level by Roche:
- CloudTrail
- Guard-Duty
What IDE software do we use?
This is very much a question of personal preference. To my knowledge, most members of our team use either VSCode or Vim. If/when members of our team settle on patterns or best practices that are worth adopting team-wide, we’ll share them here.
What’s our team’s code management/review process
- We use Git for version control.
- As of July 2022, we are just about completely migrated from GitLab to GitHub.
- We don’t have an enforced code management workflow, but we’ve started to settle on a Gitflow model.
- We are also starting to settle on semantic versioning, branching and commit messaging.
- As of July 2022, we do not YET have any branch protection strategy, but that is coming soon (as we have time).
- We encourage a non-hierarchical 4-eyeball rule for code review, but nothing is enforced. For now, use your best judgment. If it’s critical, recommend having someone else review your code. If it’s simple and non-impactful, it’s not yet required.
- As of July 2022, we are starting to implement pre-commit hooks to enforce code quality. See our terraform-ace-prod repo for installation instructions.
What’s our team’s ticket/issue management workflow
As of July 2022, as a result of our GitLab to GitHub migration, we have transitioned to ZenHub for issue/workflow management. It’s important to note that ZenHub is just a workflow management layer that sits atop GitHub issues so when you’re working in ZenHub you’re just looking at GitHub issues with some extra metadata to enable teams - via team-based ZenHub workspaces - to leverage Agile features such as sprints, burndown charts, epics and more.
The ACE-Infra ZenHub workspace can be found here. At present, this workspace is linked with our ace-infra-issues repository. This repository is where ALL ACE-Infra tickets are managed, even if we’re ultimately committing code changes via other repositories. While this isn’t required by ZenHub - ZenHub workspaces have a one-to-many relationship with GitHub repositories - our team has chosen to do this so that our users need only go to one place to manage ACE Infra requests; they should not have to decipher which code repository relates to their request.
How do we link repo commits with Git/ZenHub issues?
If you just read the previous section you may be asking yourself this question. The standard Git auto-linking rules still apply here. Just remember that given:
- all issues reside in ace-infra-issues;
- all code commits will occur in a different repository from where the issues reside (e.g. terraform-ace-prod)
you can’t use simple links such as, for example, #123 in your commits and PR’s to reference Issue #123. Instead you’ll need to use ace-infra-issues#123 to indicate that it’s Issue 123 in the ace-infra-issues repository; not Issue #123 in your local repository.
How do we share new features/work with fellow team-members? Is there a show-and-tell conducted every 2 sprints to share what we’ve done?
Full credit to our newest team-member, Parthi, for gently suggesting this great idea in the form of a question :-)
As of August 2022, we do not currently have a process for showing off work to one another, but I did suggest such a process some time ago and it was met with approval. We just haven’t formally implemented anything yet. I have taken an action item to re-suggest this - with full credit to Parthi - in our August 12 retrospective so I hope to change the answer to this question shortly thereafter.
Linux OS Package Management
Context
There are occasions when we’ll need to build OS packages for our two supported Linux operating systems.
At time of writing we have one tool for which we build our own package: Wazuh Open Source Host Intrusion Detection System, a fork of OSSEC that offers a better rules engine, ElasticStack integration and a RESTful API. Unfortunately, the only publicly available OS packages are for the client/server version, not the local version that we use.
OS package management requires a hosting solution. We initially solved this problem with Aptly and S3, but this solution had a number of issues:
- it’s a bit of work to get it going and maintain it
- it only supports Ubuntu (
deb), not CentOS (RPM)
Enter Packagecloud.
Packagecloud
Packagecloud is a hosted package repository service that supports both OS and application packages. It’s easy to use and maintain, supports public/private repos and GPG. Its free tier provides just enough storage for our needs (at this time).
At time of writing, we have a single, public, free-tier repository: gred-ace-infra/public. Why public? Because none of our packages contain any sensitive information. They’re simply OS specific packages of publicly available open source software, built for our needs. Packages are GPG signed for integrity purposes, but there is no confidentiality requirement.
The credentials for logging into Packagecloud can be found in LastPass.
More instructions on building OS packages coming later, preferably in the form of Gitlab driven pipelines. For now, for those looking to build their own OS packages, I recommend fpm.
Sudo Management
- Sudo is configured by our Ansible Base Role.
- Please see Sudo Management Procedures for making changes to gCORE defaults.
HashiCorp Vault
HashiCorp Vault was decommissioned by Todd Michael Bushnell on 30 November 2023 so please ignore any references to it throughout our documentation. All secrets were migrated to AWS Secrets Manager.
AI Application Platforms
- Sagemaker (link broken)
- Known Issues (link broken)
- Labelbox (link broken)
Disaster Recovery
See dedicated Disaster Recovery page.